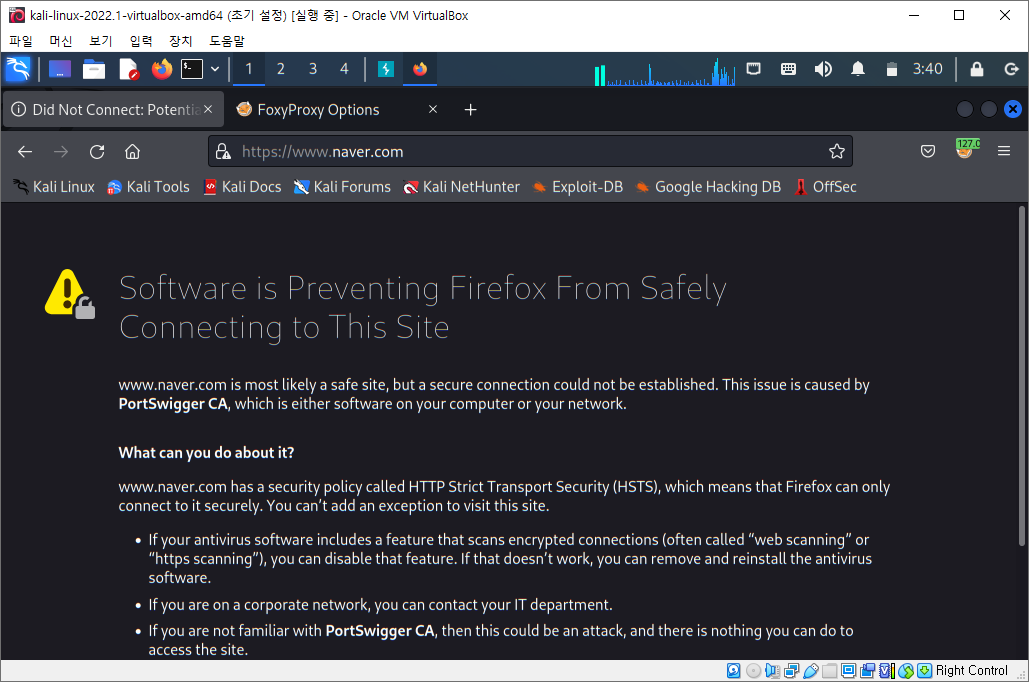
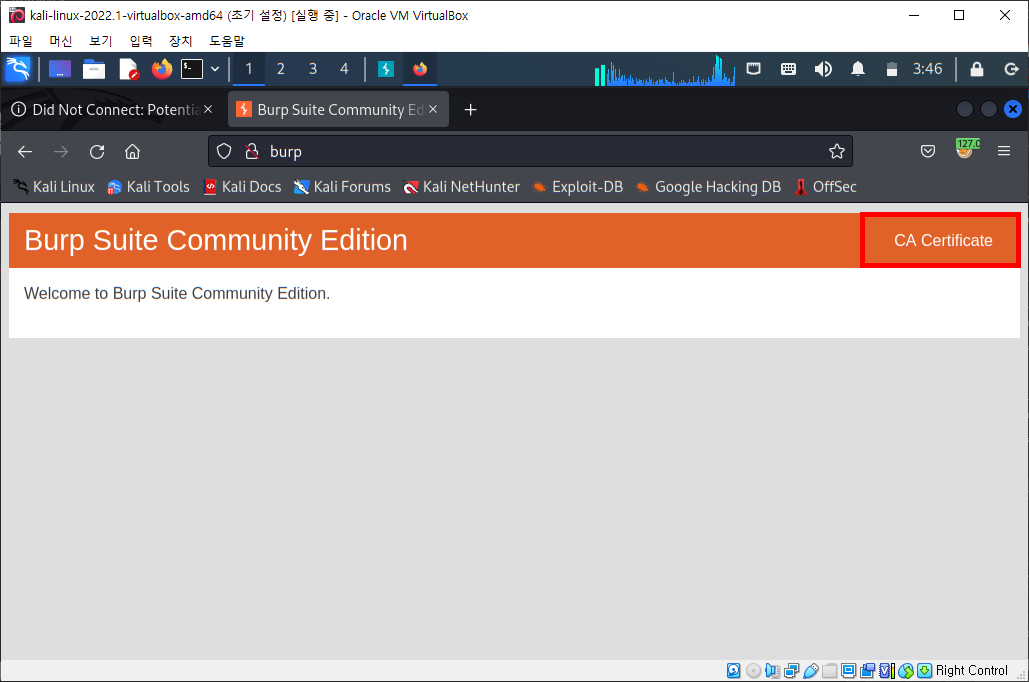
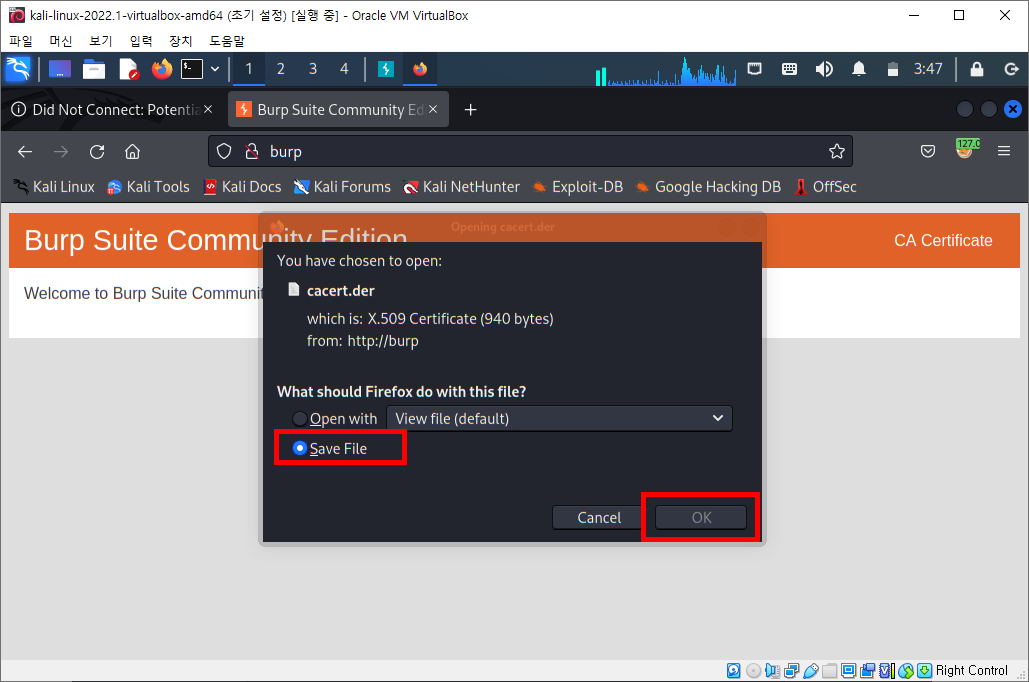
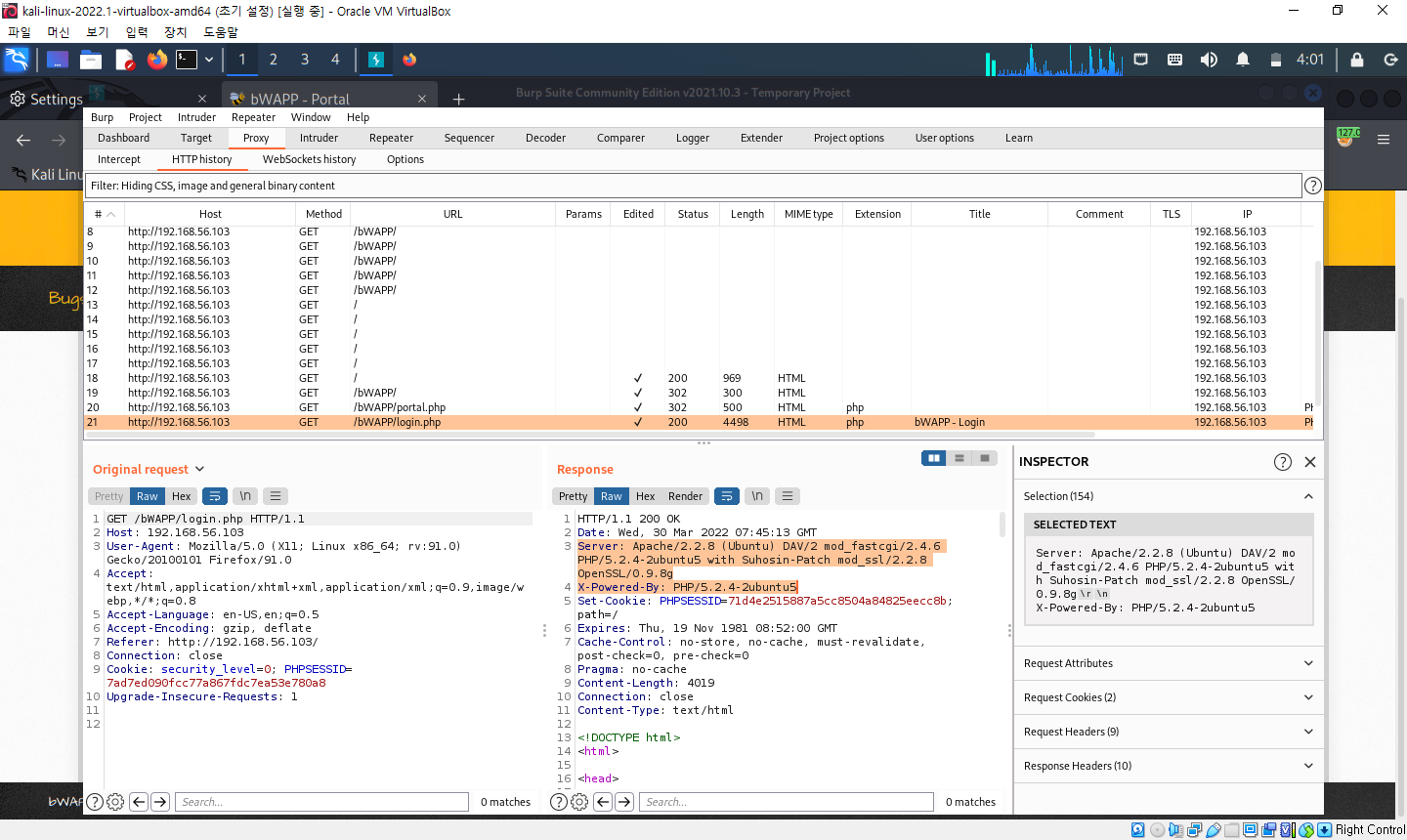
1. 배너 그래빙(banner grabbing) : 서버의 응답을 통해 정보를 수집하는 방법
- 응답 메세지의 서버 헤더를 살펴보는 것
- 개발자 도구의 네트워트 탭 -> 전송된 내역의 응답 메세지 정보 확인 (버프 스위트의 프록시 히스토리 기능에서도 확인 가능)
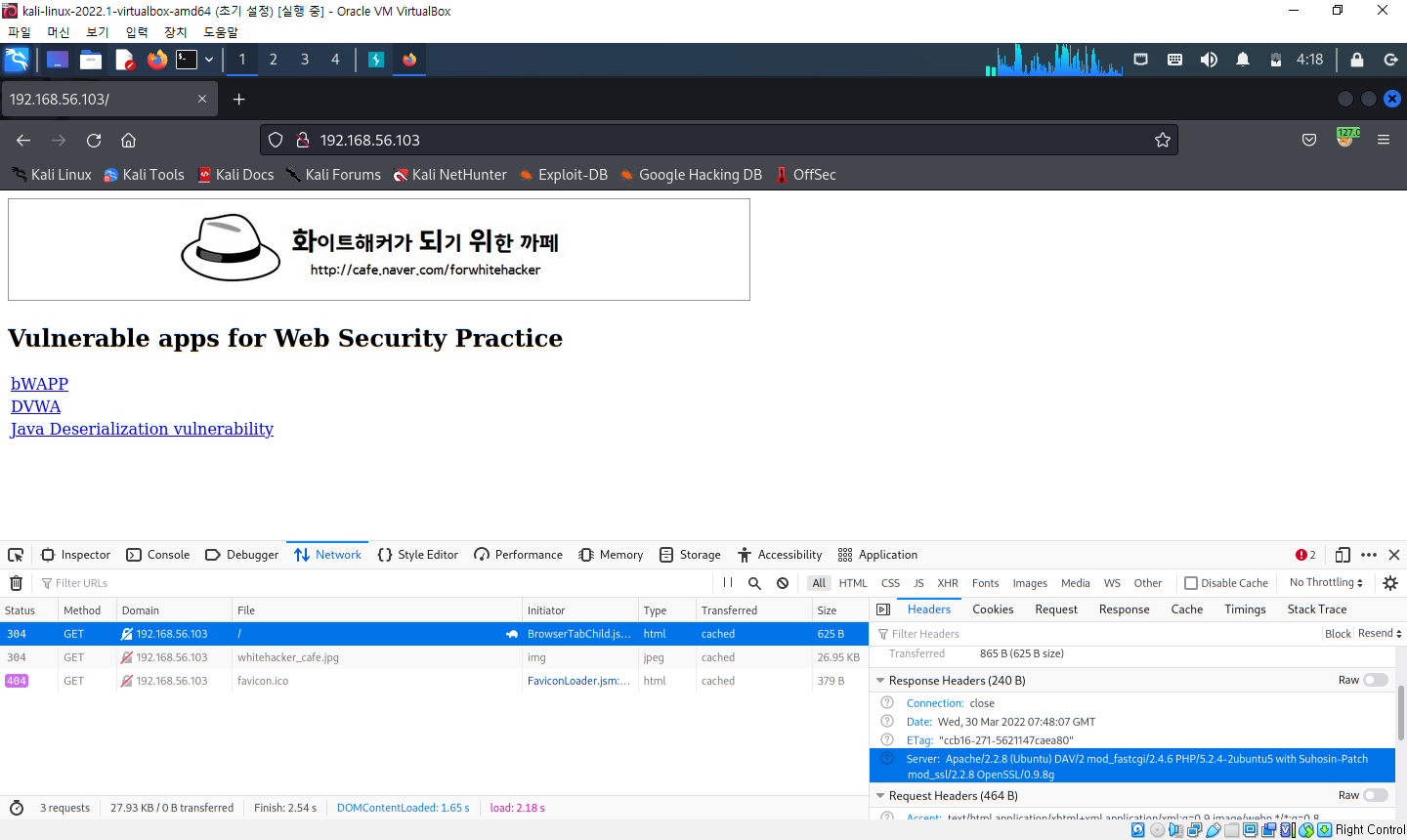
2. 기본 설치 파일로 인한 노출
- 웹 애플리케이션을 운영하기 위한 웹 서버, 웹 프레임워크, 기타 구성 요소를 설치할 때 기본으로 설치되는 파일로 인해 호스트 환경에 대한 정보가 노출되는 경우가 있음
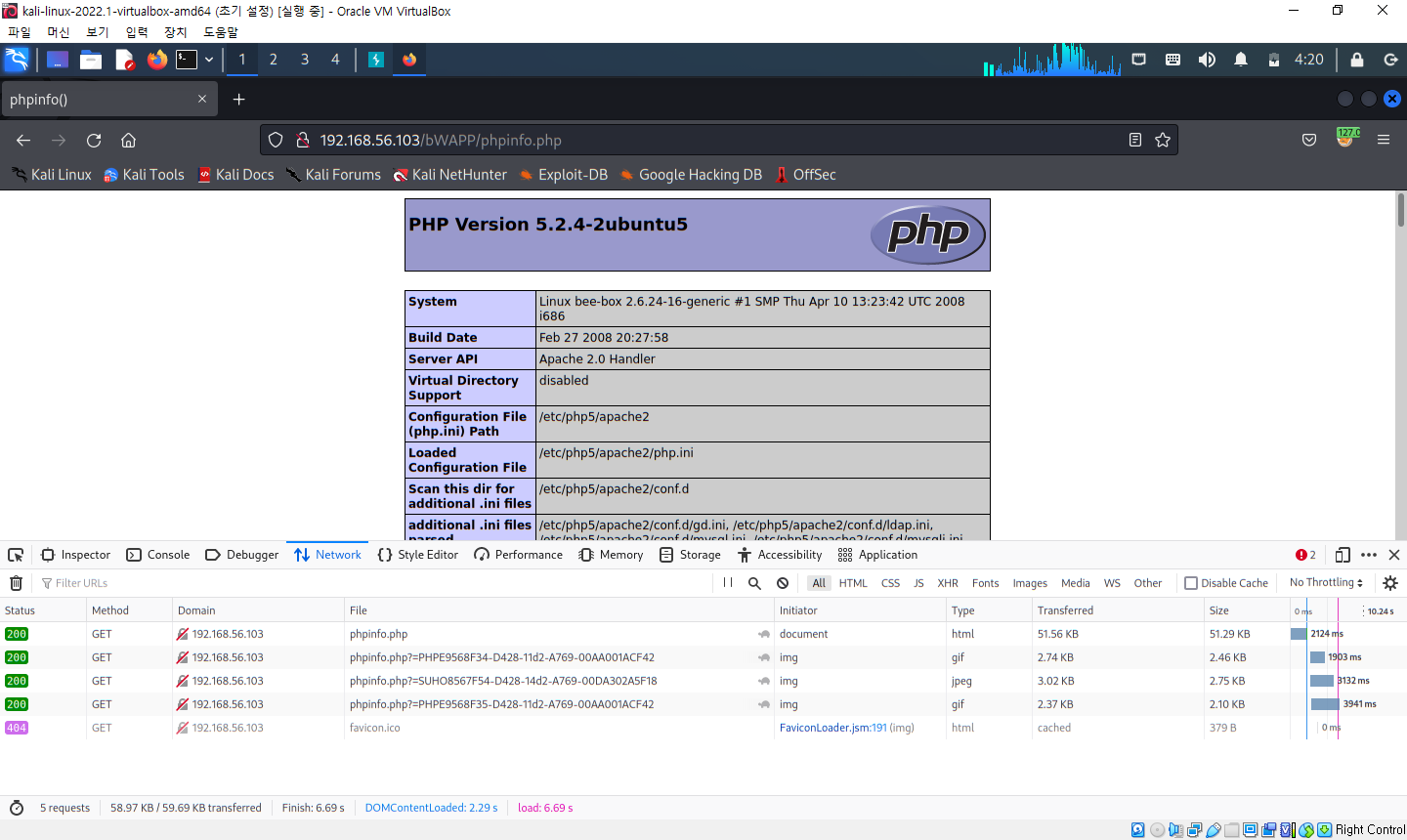
3. 웹 취약점 스캐닝
- 자동화된 프로그램을 이용하여 웹사이트의 여러 가지 정보를 수집하고 이 정보들을 바탕으로 어떤 취약점이 있는지 알아내는 과정
- 칼리 리눅스 기본 프로그램 중 nikto1이라는 프로그램을 이용하면 간단한 명령으로 중요한 정보를 쉽게 수집할 수 있음
- 터미널에 nikto를 입력하면 프로그램 사용을 위한 옵션 확인 가능
- 명령어 : nikto -host 192.168.56.103
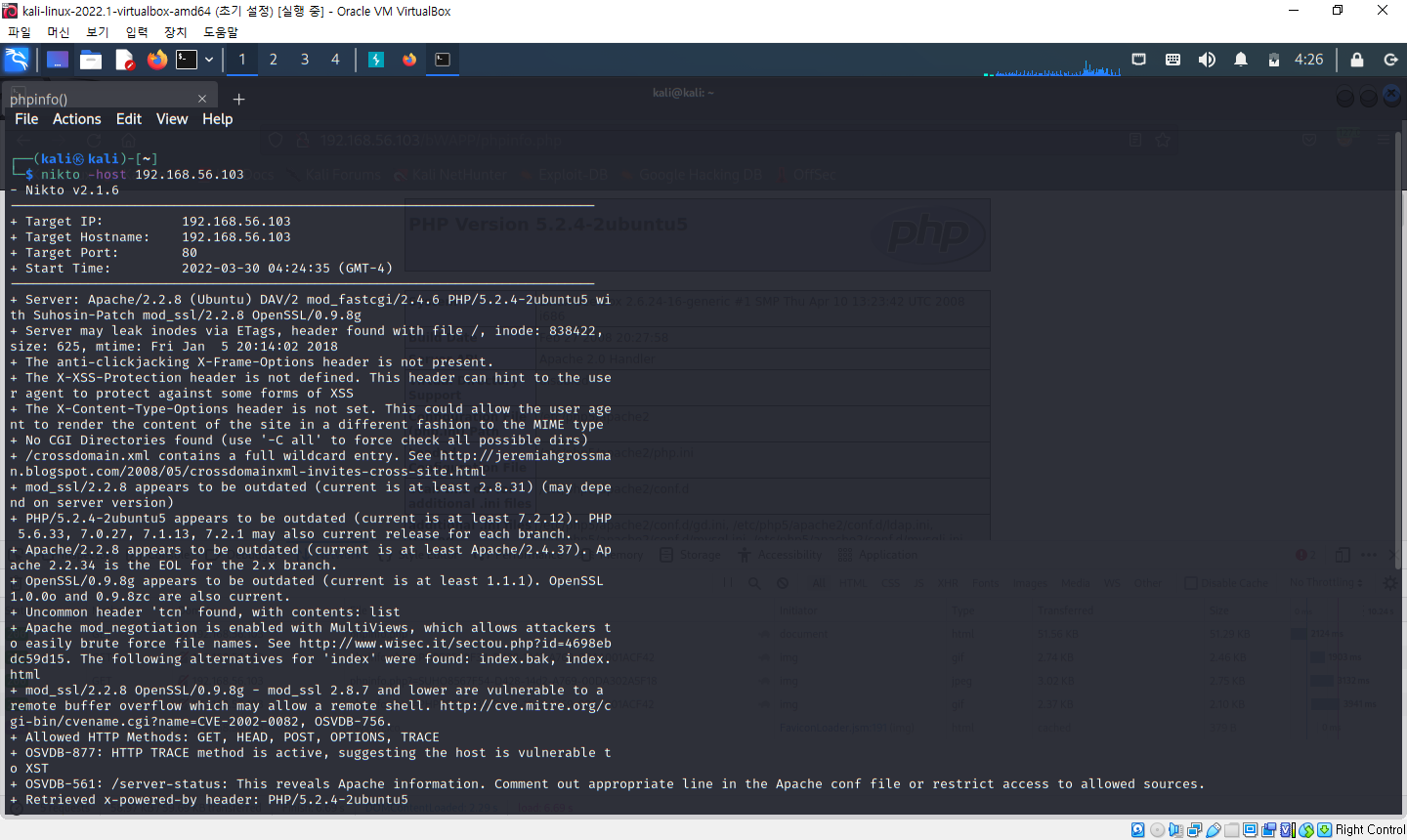
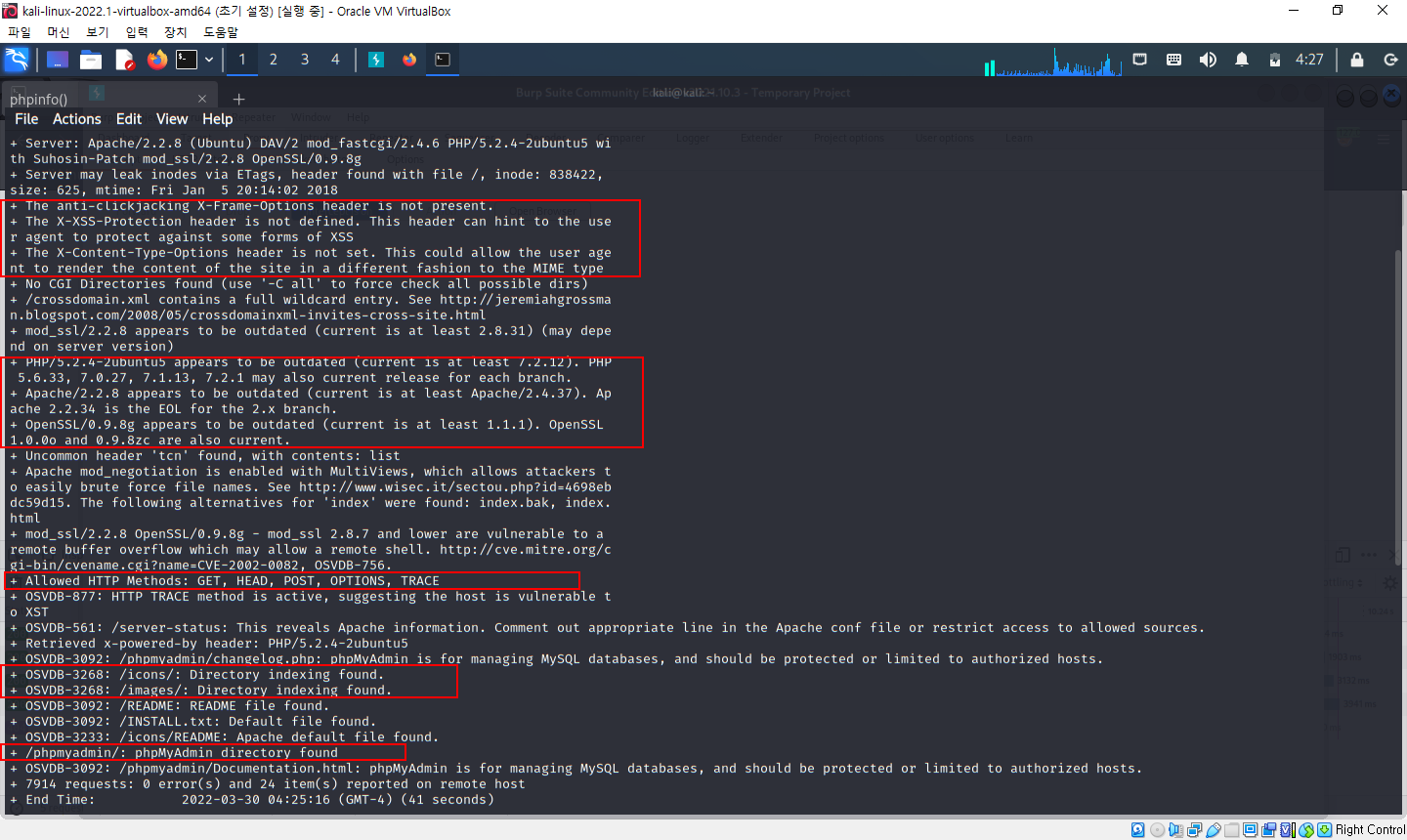
=> 빨간 박스에서 아래의 정보들을 얻을 수 있음
- 서버 헤더 및 PHP, 아파치 OpenSSL 등의 버전이 오래되었다(outdate)
- 보안 관련 헤더가 설정되어 있지 않다
- 허용된 메소드 목록 정보
- /icons/, /images/ 경로에서 디렉터리 인덱싱이 발견되었다
- phpMyAdmin 디렉터리가 발견되었다
4. 디렉터리 인덱싱
- 웹 서버의 잘못된 설정으로 웹 서버 디렉터리의 파일들이 노출되는 취약점
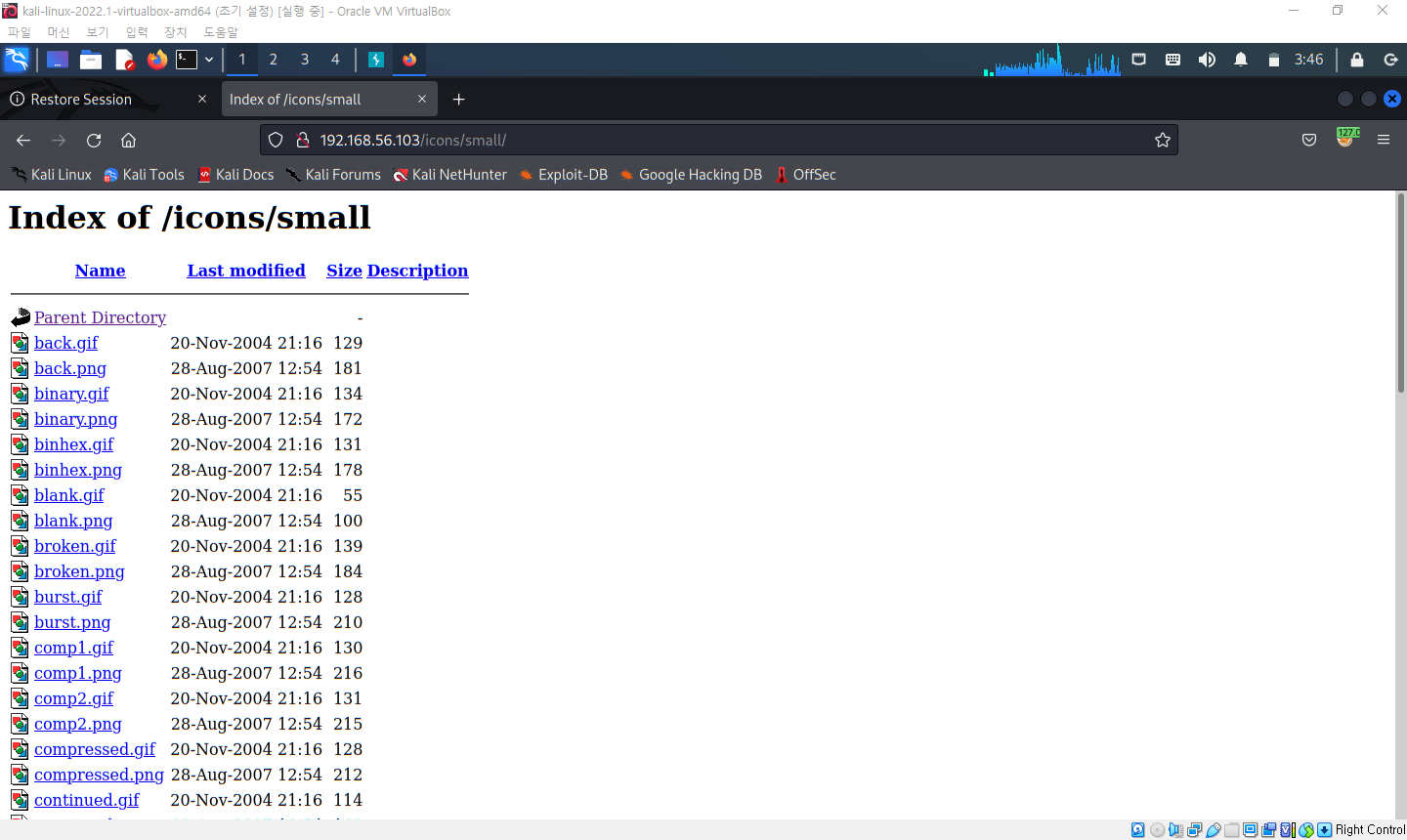
위의 경우는 icon 폴더의 파일이라서 괜찮은데, 소스코드나 개인정보가 노출되는 경우가 있기 때문에 심각한 상황이 될 수 있음
5. 웹 애플리케이션 매핑
- 마치 웹 애플리케이션의 지도를 그리듯, 웹 애플리케이션의 메뉴와 링크를 따라가면서 어떤 URL과 파라미터들이 전송되는지 구조를 파악하는 과정
- 어떤 기능을 가지고 있는지, 각 기능이 어떻게 동작하는지 쉽게 이해 가능 => 공격 지점 찾을 수 있음
6. 수동 매핑
- 직접 웹 애플리케이션에 접속하여 각 메뉴를 확인하는 과정
- 버프 스위트의 사이트 맵 기능을 활용할 수 있는데, 화면에 표시되지 않는 URL들도 자동으로 표시되기 때문에 웹 애플리케이션의 구조를 파악하는 데 많은 도움이 됨
7. 크롤링(crawling)
- 웹 페이지의 링크를 분석하여 새로운 웹 페이지를 찾아내는 과정
- 웹 애플리케이션 매핑 과정을 자동으로 수행 가능
- 순서 :
○ 처음 지정된 URL로 요청
○ 처음 요청에 의해 전송받은 응답 메세지를 분석하고 응답에 포함된 링크를 각각 추가로 요청
○ 더 이상 링크를 찾을 수 없거나 404, 500 등과 같은 에러 메세지가 응답될 때까지 과정 반복
8. DirBuster
- URL 목록 파일을 사용하여 각 URL을 자동으로 입력해보는 방식으로 구조 파악
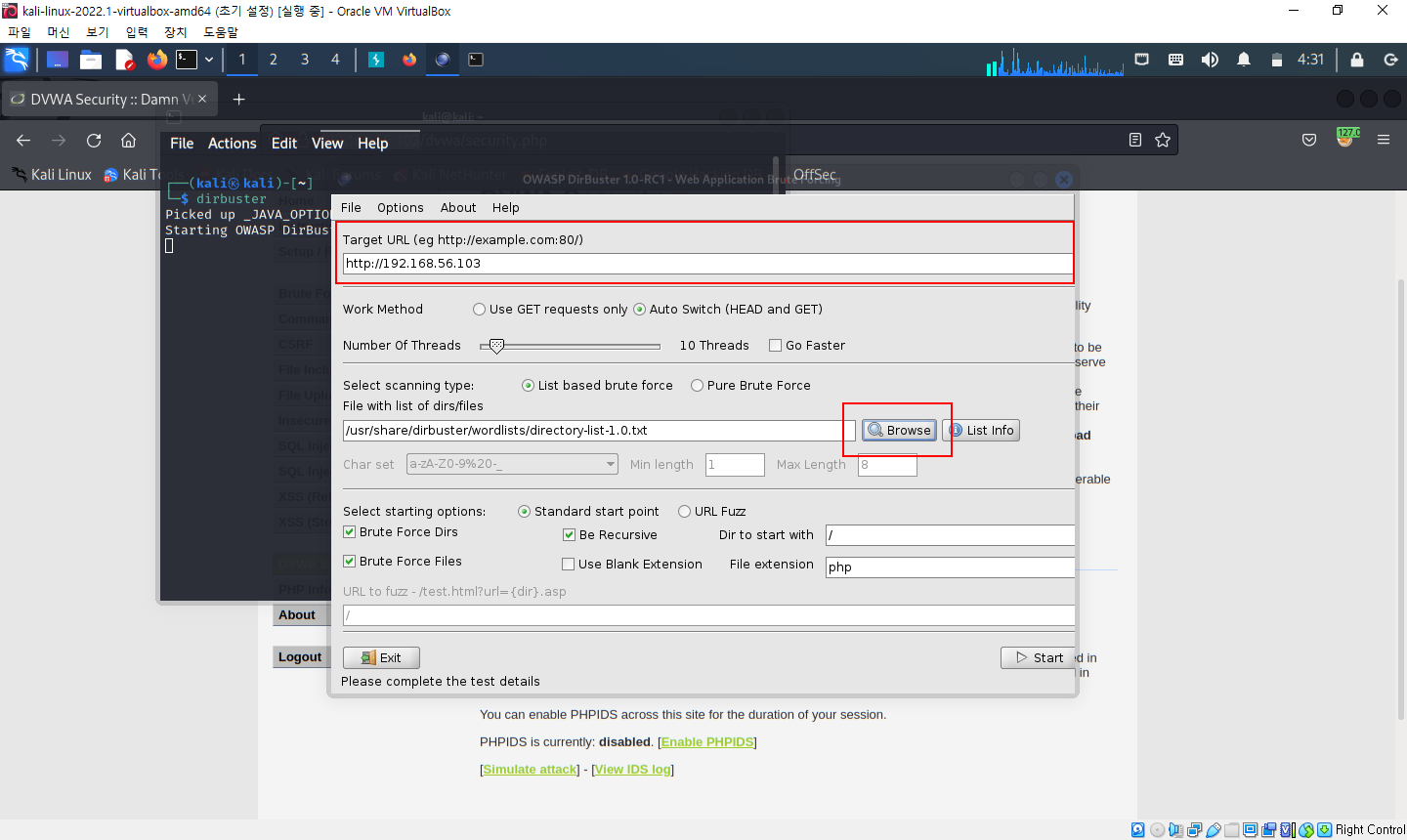
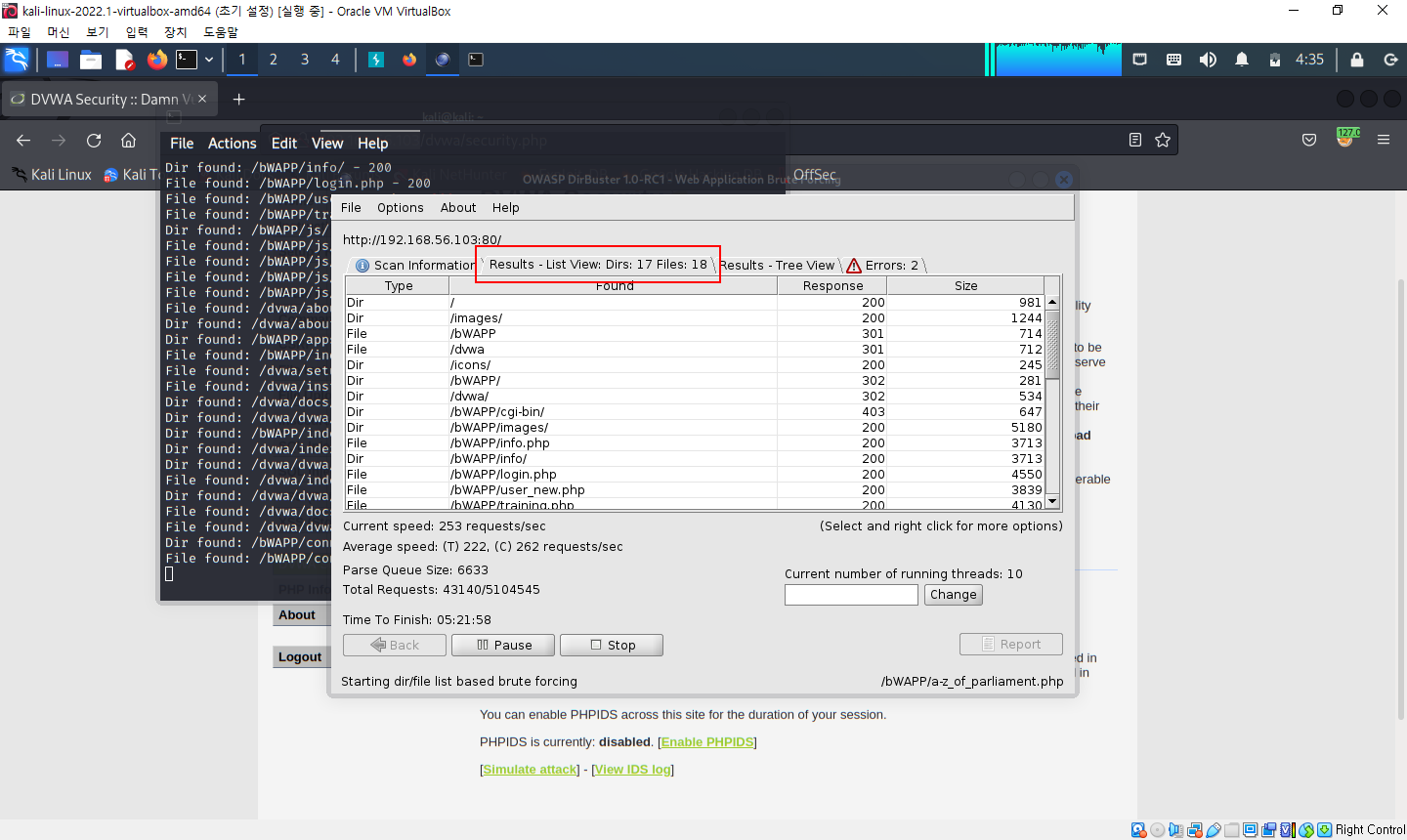
8-1. 브루트 포스 공격
- 목록 파일을 사용하여 정보를 찾는 기법
- 주로 사용자의 패스워드를 찾는데 사용하는 기법
9. robots.txt
- 웹 로봇 역시 크롤러(크롤링 프로그램)의 일종
- 웹사이트 운영자는 robots.txt 파일을 웹사이트의 가장 상위 디렉터리에 위치시켜, 웹 로봇에게 해당 웹사이트의 정보 수집을 허용하거나 불허하는 명령을 내릴 수 있음
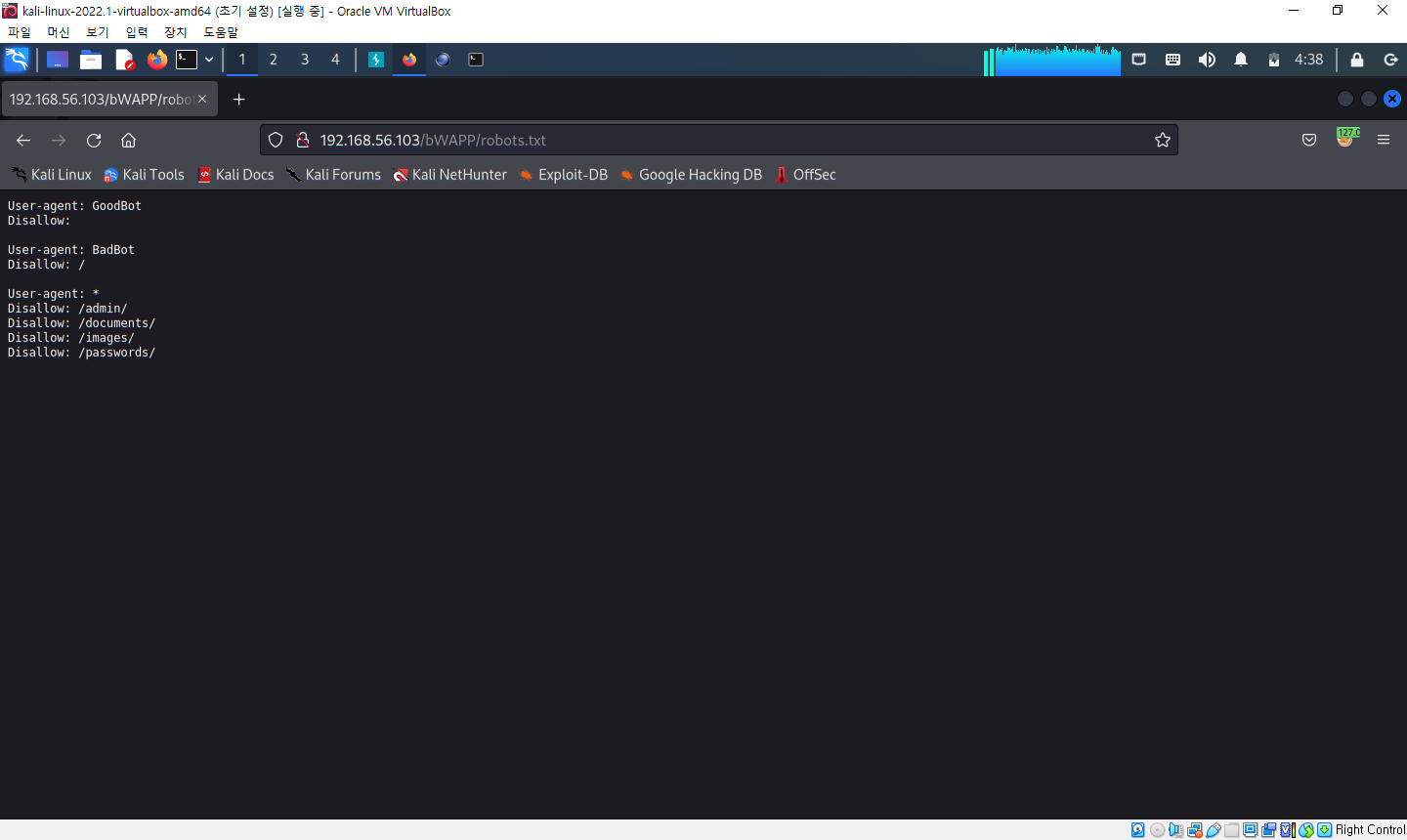
- 위의 화면에서 알 수 있는 것
○ User-agent가 GootBot인 로봇의 수집을 불허하지 않음
○ User-agent가 BadBot인 로봇은 모든 페이지에 대한 수집을 불허함
○ 모든 로봇은 /admin/, /documents/, /images/, /passwords/ 디렉터리에 대한 수집을 불허함
- robots.txt의 내용을 따를지 말지 결정하는 것은 전적으로 웹 로봇에게 달려 있음
- 중요한 경로가 노출될 수 있기 때문에 robots.txt 파일을 이용하여 보안 정책을 적용하려고 해서는 안 됨.
'공부 일지 > 웹 해킹' 카테고리의 다른 글
| [웹 해킹] 버프 스위트 관련 용어 정리 (0) | 2022.03.30 |
|---|---|
| [웹 해킹] 칼리 리눅스 2022 버전 - 버프 스위트 사용 시 HTTPS 접속 에러 해결하기 (0) | 2022.03.28 |
| [웹 해킹] 칼리 리눅스 2022 버전 - 폭시프록시 애드온 설정하기 (0) | 2022.03.28 |
| [웹 해킹] 칼리리눅스 2022 버전에서 파이어폭스 프록시 설정하기 (1) | 2022.03.17 |
| [웹 해킹] 버프 스위트 시작하기 (0) | 2022.03.17 |